主成分分析
ここでは,互いに相関のある変数群について観測された多次元データを,情報をできるだけ失うことなく,もとの変数の線形結合で表される新たな変数へ要約する手法である主成分分析を学びます.
様々な指標についてまとめて理解したいときによく使います.また,独立成分分析などの基本にもなります.さらに,高次元データを低次元(より少数の変数)へ要約する次元圧縮の手法としても用います.
主成分とは
たとえば,以下の左の図のように $x,y$ の2変数で観測されるデータ点の集合があったとします.このデータについて説明する時には,このままで議論するよりは,明らかに斜めに伸びているので回転させてあげて,伸びる方向を軸とした方が楽そうです.
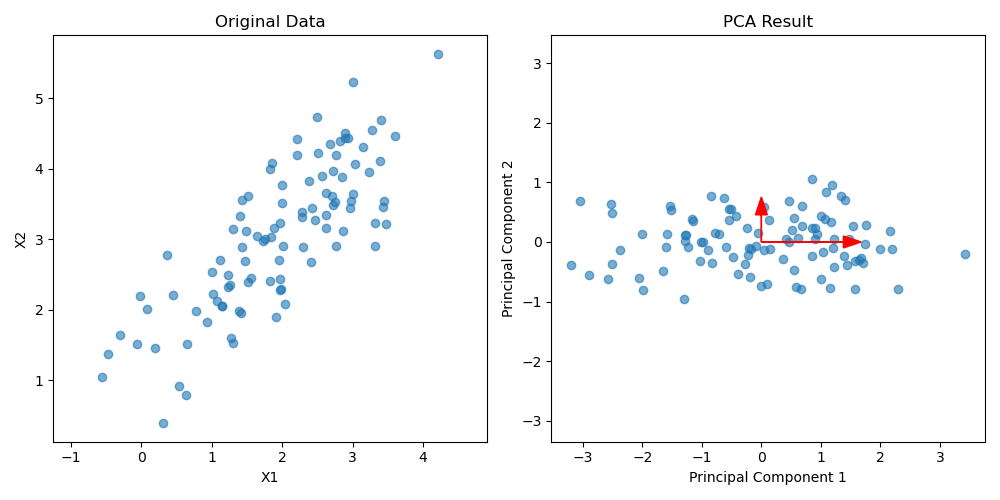
右側の図が,実際にその作業をやった図で,これこそがPCAの結果でもあります.見れば分かりますが,回転させていますね.
こうすることで,もはや最初の $x,y$ という軸ではなくなってしまいましたが,新しい軸 Component1, Component2 の下で考えるなら Component2 はあまり考慮しなくても良さそうです.明らかに横方向の広がりの方が大きいですしね.
と,いう考え方に従ってComponent2の成分を無視するのが,次元圧縮です.元々は $x,y$ という2変数だったのが, Component1 という1変数のデータに置き換わりました.
今は2次元だったので,あまり有用性が分からなかったかもしれませんが,これがたとえば30変数のデータだったらどうでしょう.とてもありがたいはずです.
このように,「元のデータの情報をできるだけ失うことなく,新しく定義した軸」を主成分といいます.では,そんな軸はどうやって定めるのでしょうか.
分散と主成分
結論から言うと,分散を最大化することになります.分散とは,平均からの広がりでした.
まずは,新しい軸を定義した時に,各データをその軸上に垂直におろしてきます(射影).そうすることで,新しい軸成分にどれだけの値なのかが分かります.(よく分からない場合,$x,y$平面では各点を $x$ 軸,$y$ 軸に落とした値でデータを表現していることを思い出してください)
そうすると,その軸方向の「平均値」が求まります.
で,今回注目するのは分散でしたが,これは平均値から各点が平均的にどれだけ離れているのかを表すための量です.各点がばらつくほど大きな値ですね.
分散を最大化するというのは,新しく定義した軸方向にデータが大きく広がっている,という意味になります.
再びこの図を眺めてみれば,意図が分かるはずです.一番データが広がる方向が,すなわち一番データを説明できそうな「軸」になるわけですね.右のPCAの図も,実際に一番分散が大きくなる方向を横軸 (長い赤矢印) にとっています.
第n主成分
こうして得られた,「最も大きな分散になる射影軸」を第1主成分と言います.
さらに,第1主成分と直交するという条件のもとで,次に分散を最大化する射影軸を第2主成分と言います.上の図は元々2次元のデータなのでここまでですが,元のデータの次元が $n$ あれば第n主成分まで求めることが出来,その求め方は第2主成分以降は同じです.
こうして得られた主成分のうち,上位いくつかだけを選んでデータを表現することで,上手くいけばデータを $n$ より遥かに小さい次元数で記述することが出来るようになります.
求め方
では,求めていきます.簡単のため,とりあえず2次元で考えます.
まず,求めたい射影軸を
\[\begin{align} y = w_1 x_1 + w_2 x_2 \end{align}\]と定義します.ここで,$x_1, x_2$ は元データの次元です.英語と数学の点数,身長と体重,年収と寿命,そんな感じです.
そして,元々の $n$ 個の 2 次元データを
\[\bm{x}_1 = \begin{pmatrix} x_{11} \\ x_{12} \\ \end{pmatrix}, ..., \bm{x}_n = \begin{pmatrix} x_{n1} \\ x_{n2} \\ \end{pmatrix}\]とします.さらに
\[\bm{w} = \begin{pmatrix} w_{1} \\ w_{2} \\ \end{pmatrix}\]として,$\bm{x}$ をそれぞれ式 (1) の射影軸に射影すると,
\[\begin{align} y_i = w_1 x_{i1} + w_2 x_{i2} = \bm{w}^T \bm{x}_i, \quad i=1,2,...,n \end{align}\]と書けます.とりあえず,これで軸 $y$ に対して2次元データ群 $\bm{x}$ を射影できました.
平均と分散
次は,この軸上での分散を求めます.が,そのためにはまず平均が必要です.
\[\begin{align} \bar{y} &= \frac{1}{n} \sum_{i=1}^n y_i = \frac{1}{n} \sum_{i=1}^n (w_1 x_{i1} + w_2 x_{i2}) \nonumber \\ &= \bm{w}^T \bm{\bar{x}} \end{align}\]となります.ここで $\bm{\bar{x}} = (\bar{x}_1, \bar{x}_2)^T$ です.平均が求まったので,分散を求めます.普通に計算していくと,
\[\begin{align} s^2_y &= \frac{1}{n} \sum_{i=1}^n (y_i - \bar{y})^2 \nonumber \\ &= \frac{1}{n} \sum_{i=1}^n \{ w_1 (x_{i1} - \bar{x}_1) + w_2 (x_{i2} - \bar{x}_2) \}^2 \nonumber \\ &= w_1^2 \frac{1}{n} \sum_{i=1}^n(x_{i1} - \bar{x}_{1})^2 + 2w_1 w_2 \frac{1}{n} \sum_{i=1}^n (x_{i1} - \bar{x}_{1})(x_{i2} - \bar{x}_{2}) \nonumber\\ & + w_2^2 \frac{1}{n} \sum_{i=1}^n(x_{i2} - \bar{x}_{2})^2 \nonumber \\ &= w_1^2s_{11} + 2w_1w_2s_{12} + w_2^2s_{22} \nonumber \\ \end{align}\]と,なります.最後に,標本分散共分散行列の記法
\[S = \begin{pmatrix} s_{11} & s_{12}\\ s_{21} & s_{22} \end{pmatrix}, s_{jk} = \frac{1}{n}\sum_{i=1}^n(x_{jk} - \bar{x}_{j})(x_{jk} - \bar{k}_{2})\]を使うことで,
\[\begin{align} s_y^2= \bm{w}^T S \bm{w} \end{align}\]と,分散をまとめられます.
第1主成分を求める.
では,主成分を求めます.おさらいすると,求める軸 $y$ に射影した $n$ の分散が最大化されるような $\bm{w}$ を求める問題です.ここで,当然の話として $\bm{w}$ にくそでかい値を持ってくれば,分散も無限に大きくなってしまいます.これでは意味がないので,制約条件として
\[\begin{align} \bm{w}^T \bm{w} = 1 \end{align}\]を設けます.
これにより,制約条件(5)の下での条件付き極値問題となりますので,ラグランジュの未定乗数法を用いることができます.
この場合,ラグランジュ関数は
\[\begin{align} L(\bm{w}, \lambda) = \bm{w}^TS\bm{w} + \lambda(1-\bm{w}^T \bm{w}) \end{align}\]になります.こいつを $\bm{w}$ で偏微分してあげると,
\[\begin{align} \frac{\partial L}{\partial \bm{w}} &= \frac{\partial L}{\partial \bm{w}}(\bm{w}^TS\bm{w}) + \frac{\partial L}{\partial \bm{w}} \{ \lambda(1-\bm{w}^T \bm{w})\} \nonumber \\[1em] &= 2S\bm{w} - 2\lambda \bm{w} \end{align}\]となります.よって,結局分散が最大化されるような $\bm{w}$ については式 (7) より
\[\begin{align} S\bm{w} = \lambda \bm{w} \end{align}\]が求まり,求める $\bm{w}$ は標本分散共分散行列 $S$ の最大固有値 $\lambda_1$ に対応する固有ベクトル $\bm{w_1}$である事が分かります.
従って,ここで求めていた第1主成分は
\[\begin{align} y_1 = w_{11}x_1 + w_{12}x_2 = \bm{w}_1^T\bm{x} \end{align}\]であることが分かります.さらに,第1主成分 $y_1$ の分散は,式(4)
\[s_y^2= \bm{w}^T S \bm{w}\]で求まりますが,ここで
\[S\bm{w}_1 = \lambda_1 \bm{w}_1\]の両辺に左から $\bm{w}_1^T$ をかけることで得られる
\[\bm{w}_1^T S\bm{w}_1 = \lambda_1 \bm{w}_1^T\bm{w}_1 = \lambda_1\]を考えると,
\[s_y^2= \bm{w}^T S \bm{w} = \lambda_1\]となり,第1主成分の分散は第1固有値の値であることが分かります.
第2主成分
では,第2主成分を求めます.次に求める問題は,与えられた $n$ 個の2次元データを $y_2 = w_1x_1 + w_2 x_2$ へ射影した際,第1主成分の時同様に制約条件 (5) の $\bm{w}^T \bm{w} = 1$ に加え,先程求めた第1主成分 $y_1$ と直交する,すなわち
\[\begin{align} \bm{w}_1^T \bm{w} = 0 \end{align}\]という新しい制約条件の下で $\bm{w}^TS\bm{w}$ を最大化する $\bm{w}$ を求める問題になります.ラグランジュ関数は
\[\begin{align} L(\bm{w}, \lambda, \gamma) = \bm{w}^TS\bm{w} + \lambda(1-\bm{w}^T \bm{w}) + \gamma \bm{w}_1^T \bm{w} \end{align}\]になります.偏微分して0とおいてみると,
\[\begin{align} \frac{\partial L}{\partial \bm{w}} &= \frac{\partial L}{\partial \bm{w}}(\bm{w}^TS\bm{w}) + \frac{\partial L}{\partial \bm{w}} \{ \lambda(1-\bm{w}^T \bm{w})\} + \frac{\partial L}{\partial \bm{w}} \{\gamma \bm{w}_1^T \bm{w}\} \nonumber \\[1em] &= 2S\bm{w} - 2\lambda \bm{w} + \gamma \bm{w}_1 =0 \end{align}\]となります.
ここで,式 (12) の各項に左から $\bm{w}_1 ^T$ をかけてみると,
\[2\bm{w}_1 ^TS\bm{w} - 2\lambda \bm{w}_1 ^T\bm{w} + \gamma \bm{w}_1 ^T \bm{w}_1\]となり,制約条件から
\[\begin{align} 2\bm{w}_1 ^TS\bm{w} + \gamma = 0 \end{align}\]となります.$S\bm{w}_1 = \lambda \bm{w}_1$であることを考えると,$\bm{w}_1^TS = \lambda_1 \bm{w}_1 ^T$でもあるので,式 (13) の $2\bm{w}_1 ^TS\bm{w}$は $2\bm{w}_1 ^TS\bm{w} = 2 \lambda_1 \bm{w}_1^T \bm{w} = 0$ となるので,$\gamma=0$であることが分かります.
ということで,式 (12) に$\gamma=0$をいれると
\[\begin{align} 2S\bm{w} - 2\lambda \bm{w} + \gamma \bm{w}_1 &=0 \nonumber \\ 2S\bm{w} - 2\lambda \bm{w} &= 0 \nonumber \\ \therefore S\bm{w} &= \lambda \bm{w} \end{align}\]となり,結局のところ第2主成分についても,解$\bm{w}$は標本分散共分散行列の2番目の固有値 $\lambda_2$ に対応する固有ベクトル $\bm{w}_2$ であり,分散は $\lambda_2$ となります.
よって,第2主成分は
\[\begin{align} y_2 = w_{21}x_1 + w_{22}x_2 = \bm{w}_2 ^T \bm{x} \end{align}\]になります.
まとめ
結局,主成分分析が行う,分散を最大化する軸を順に見つけて射影していくという問題は,標本分散共分散行列$S$の固有値問題に帰着されることが分かりました.
一般に,変数が $m$ 個あるデータ $\bm{x} = (x_1, x_2, …, x_m)^T$ が $n$ 個観測されたとき,標本分散共分散行列 $S$ の固有値を
\[\lambda_1 \geq \lambda_2 \geq ... \geq \lambda_m\]として,対応する長さ1に正規化された $m$ 次元の固有ベクトルを
\[\bm{w}_m = \begin{pmatrix} w_{m1}\\ w_{m2}\\ \vdots\\ w_{mm} \end{pmatrix}\]とすると,第 $m$ 主成分とその分散は \(y_m = \bm{w}_m^T \bm{x}, \quad \text{var}(y_m) = \lambda_m\)
で求められることになります.