| 目次 | Experiment |
Simulations非線形力学 |
|---|
01実行環境について
本編でシミュレーションやデモを構築,実行していく環境,およびその構築方法についてまとめておきます.基本的に,言語はPythonを使用していきます.
(Juliaも使ってみることがあるので,別のページで環境構築をしておきます.)
Jupyter notebookの導入
Jupyter Notebookとは,ブラウザ上で対話形式にプログラムを実行できる環境です.データ分析によく使うツールの1つです.
![]()
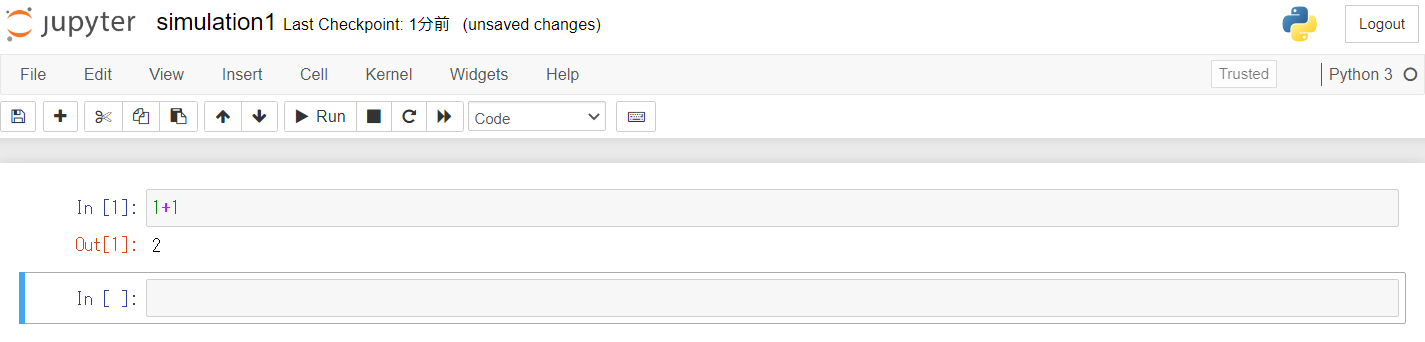
Jupyter Notebook上でプログラム開発,実行を行うメリットは,プログラムを途中で切って個別に実行していくことが出来ることにあります.これにより,結果をすぐに,段階的に見ることが出来ますし,デバッグも楽になります.
このため,初心者に優しく,また開発中やデバッグ中のお試し計算量(時間)も落とすことが出来ます.
今回は,そんなJupyter Notebookを使ってPythonのプログラムを開発する環境を整えていきます.プログラミング言語としてPythonを採択する理由は,まず第一に無料であること,ニューラルネットに関係するライブラリや資料がありふれていること,ユーザ数が多いことなどです.
Anacondaのインストール
はじめに,Jupyter NotebookをいれるためにAnacondaと呼ばれる,データサイエンスに特化したPythonおよびRの無料のディストリビューションを入れていきます.
AnacondaはOSに制限なく,いれるだけでデータサイエンスに使うパッケージはだいたい一緒にインストールされ,また開発環境の整備などの面で強力なサポートを持つという優れモノです.
Pythonを使ってプログラミングを始めようとすると,だいたいの初心者が開発環境の構築に苦しむことになりますが,それを(ある程度)避けられます.というのも,Pythonは様々なライブラリから必要な関数,モジュールをimportして使っていくのですが,これらのバージョンが合っていないと衝突して上手く動かないなんてことがよく起きるのです.Anacondaはそこらへんを精査してくれます.
さっそく入れていきましょう.
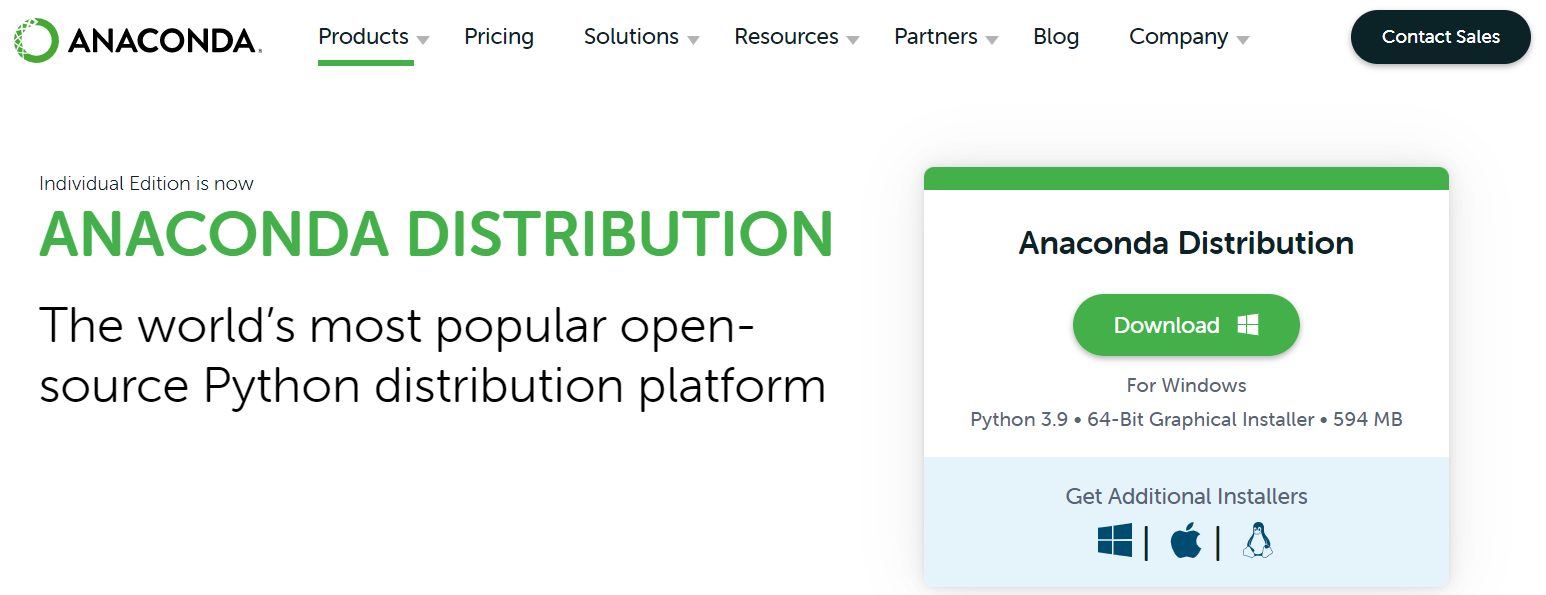
自身のOSにあったバージョンを選択し,Download,Installしてください.Next,I agreeなどを押してデフォルトのまま進めます.
Anacondaのインストール先を選択する際,基本的にはデフォルトのままで良いのですが,日本語のフォルダが含まれているとエラーを吐くらしいので,その場合は適宜インストール先を変更してください.
途中でてくるpathのAdvanced optionはやらなくて良いので,そのままInstall.
Anacondaの起動
Installが上手くいっていれば,WindowsやMacの検索でAnacondaと打つとAnaconda Navigatorがいるはずです.起動します.

いろんなアプリが表示されているはずです.ここから,更に使いたいものをInstallすることで,使用できるLaunchの表示に切り替わります.
簡単な説明に書いてある通り,それぞれPythonやR(特にVScodeなんかは他にも使える)の統合開発環境ですので,便利です.今回の本命であるJupyter Notebook以外にも,VScode, RStudioあたりは使っている人がかなり多いですね.
多分,Jupyter Notebookは初期の段階でInstall済みになっているはずです.なっていなければInstallしてください.これでPythonの開発環境が(ひとまず)整いました.
Jupyter Notebookの起動
では早速,Jupyter Notebookを起動します.Launchを押してください.あるいは,OSの検索画面から直接起動しても構いません.自分は普段そうしています.
どちらでもOKです.
起動すると,なにやら黒い画面が起動し,
その後ブラウザが開いて,このような画面が表示されるはずです.されない場合,黒い画面の下の方に「このurlをブラウザで検索してね」みたいなメッセージが表示されているはずなので,それに従うと下の画面に移ります.
ここに表示されているフォルダは,ご自身のローカルのものです.開発ファイルを起きたい場所にディレクトリ操作で移動します.
移動したら,そこで右上のNewからPython3を選択し,新しくファイルを作成します.
開いたらまず,名前をつけましょう.最初はUntitleになっている左上のファイル名をクリックし,任意の名前に変えます.
これで準備完了です.
動作テスト
いよいよ,Jupyterを使ったPythonプログラムの開発です.Jupyter Notebookでは,セルと呼ばれる単位ごとにプログラムを実行させていきます.Inの[]の中には,そのセルが実行された順番が表示されています.
これを使って,セルをあえて1個飛ばして実行するというようなことも可能です.
- セル間の移動は,移動したいセルをクリック
- セルの実行はWindowsなら
Ctrl-Enter,Macは⌘-Enter(たしか) - セルを実行して次のセルに移る場合は,
Shift-Enter

いくつかのセルを作って,色々試してみましょう.ついでに,その他のメニューの操作も軽く確認しておきます.
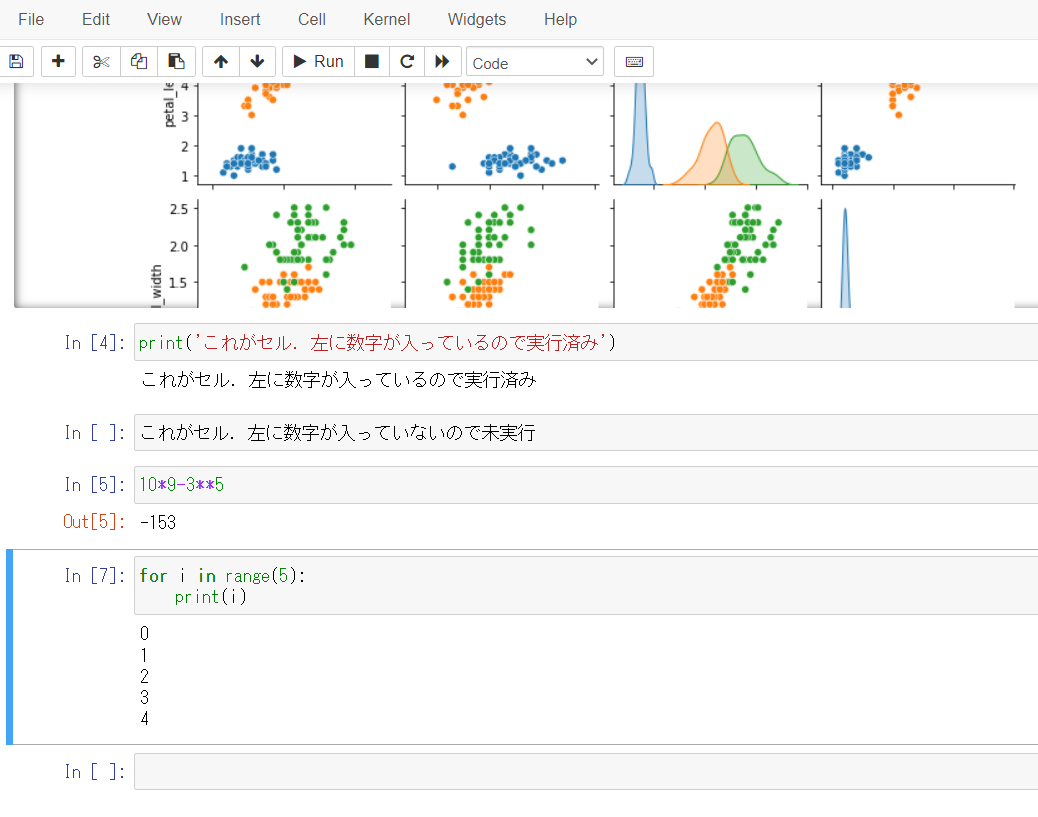
上にあるFileなどからは,よくある保存などの操作が行えます.自分は基本的には使わないです.保存はCtrl-sで出来ますし.
同じく,その下のフロッピーアイコンからも保存が,+アイコンからはセルの追加が,といったようにセル操作が可能です.が,こちらも自分は基本コマンドで行っています.
コマンドを使ったその他の操作については,Shortcutsを参照してください.
とりあえず,この一連の操作が出来たら基本的な使い方は問題ありません.
その他の便利機能
Markdown
Jupyter Notebookにはこれ以外にも,様々な便利機能があります.たとえば,Markdown記法.
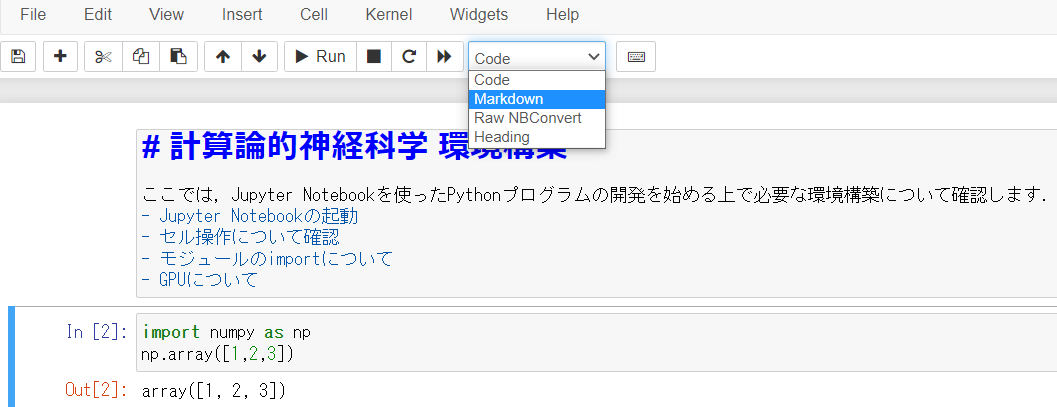
セルの設定をcodeからmarkdownに変更することで,Notebook内にMarkdownのメモを入れ込むことが出来ます.他の環境では頑張ってコメントアウトしていても,箇条書きだとかハイライトだとか,分かりやすい記法が出来ないせいでイマイチ伝わらない...そんなことありますよね.
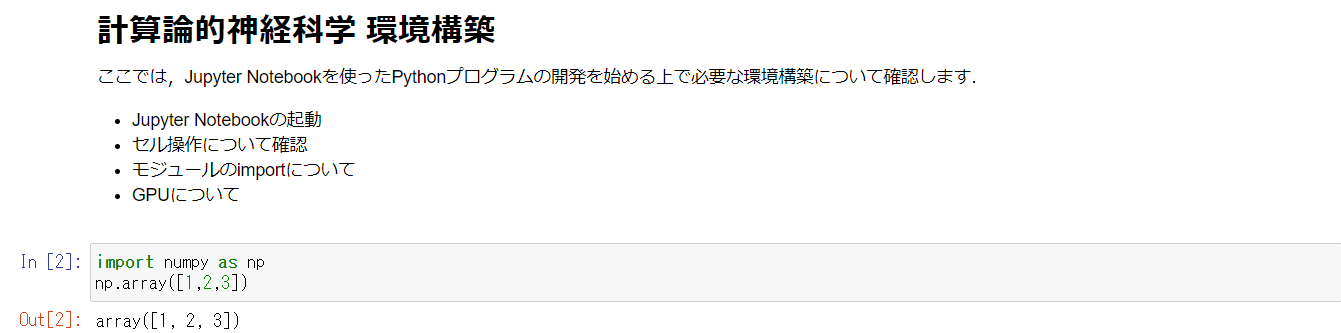
Markdownセルを実行すると,こんな感じになります.便利ですね.
.pyの出力
Jupyter Notebookを使ってpythonのプログラム開発を行うと,ファイルの拡張子は.ipynbという特殊なものになります.これはNotebookでしか実行できないファイルなので,シンプルなpythonプログラムとして実行したかったり,作成したプログラムをモジュール化して別のプログラムにimportしたくなった時には.pyとして保存する必要があります.
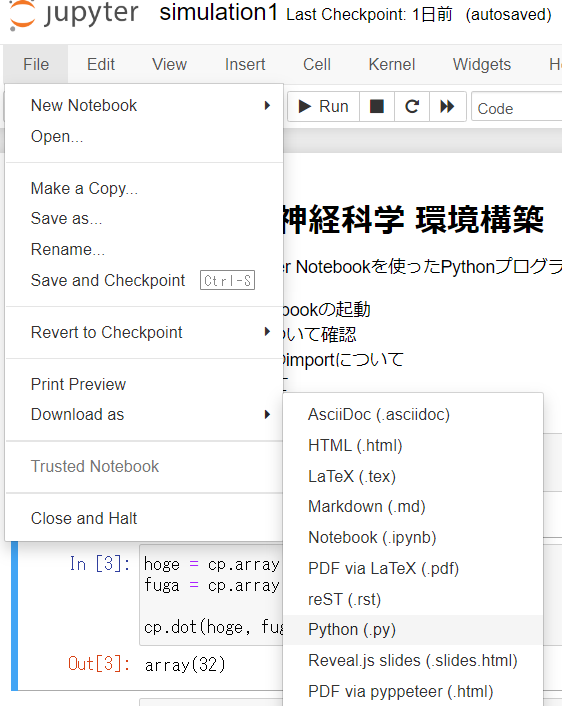
そんな時には,Fileメニューから.pyとしてダウンロードすることが可能です.
他にも,様々な拡張子でのダウンロード,というより変換が可能です.Print Previewからでも良いですが,たとえばpdfに変換することで,Notebookの内容をそのまま,つまりコードも書かれた状態で共有することが出来ます.markdownの説明なんかも挟んでいれば,ミーティングとかに使うには便利ですね.
他者との共有
Notebookは他者と共有して使うことも可能です.が,今回は自分がぼっちであまり良さを魅せられないので割愛します.仲間がいる人は調べてみてください.
GPUの使用
マストではありません.
GPUとは何か,といった話は割愛します.分からない人のために,語弊を招きつつもメリットだけ説明すると,ここでは(特定の条件下では)計算が超早くなる方法を説明していきます.
とはいえ,普通に使っている分には問題ありません.大規模な計算を回すようになり,高速化を求めるようになった場合に検討する事項です.
さて,早速GPUを使ってJupyter notebook, というよりpythonのプログラミングをしていく準備を整えます.かなり面倒です.
GPUドライバのインストール
まずはGPUのドライバをインストールします.いや,その前にGPUが入っているか確認しましょう.Windowsならデバイスマネージャーを起動し,ディスプレイアダプターを確認します.

ここに,NVIDIAと頭についたものがあればOKです.無ければ以降の設定は出来ません.頑張ってお金を稼ぎましょう.
既に入っていれば問題ありませんが,何もしていない場合にはGPUのドライバをインストールする必要があります.PCの検索でNVIDIA Control Panelが見つからない,あるいはエラーで開けない場合,インストールしてくる必要があります.
NVIDIAのダウンロードページから,自分のGPUにあったドライバをインストールしてきます.
たとえば自分は
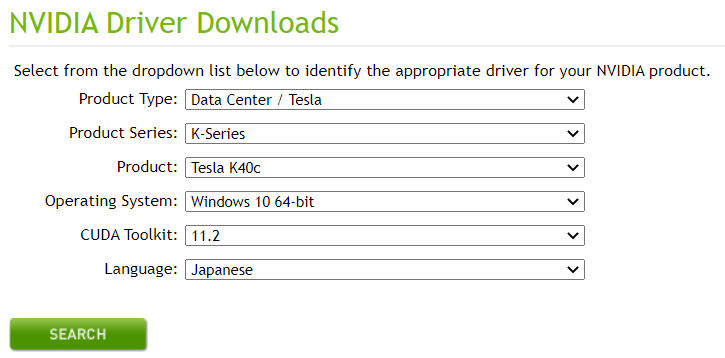
ですね.入力した内容が正しいことを確認し,ダウンロードしましょう.
ここでCUDA Toolkitが入っていない場合には,こちらも入れる必要があります.(多分です.自分は先にCUDAを入れていたので分かりません)
CUDA Toolkitをインストールする際,GPUのバージョンにあったドライバが自動でインストールされるらしいです.最初からこちらをやるでも良いかもですね.
CUDA Toolkitから,こちらも同様に自身の環境に合うバージョンをダウンロードしてください.networkでもlocalでも構わないらしいです.
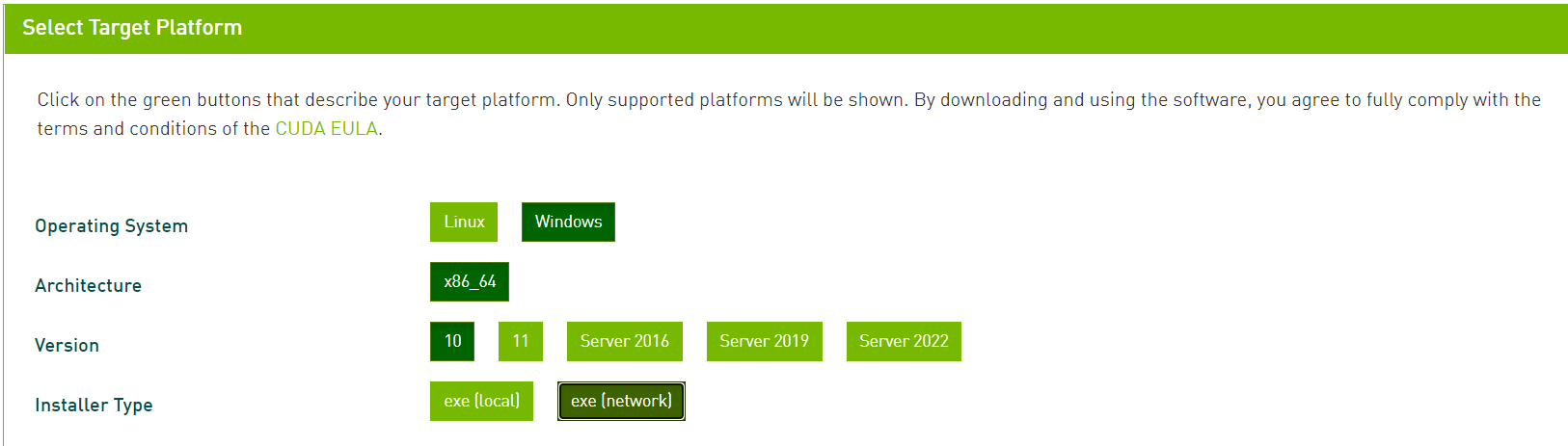
インストール時のoptionは基本的にデフォルト設定からいじらず,インストールします.
さて,どちらも無事に終わっていれば,NVIDIA Control Panelが開けるはずです.
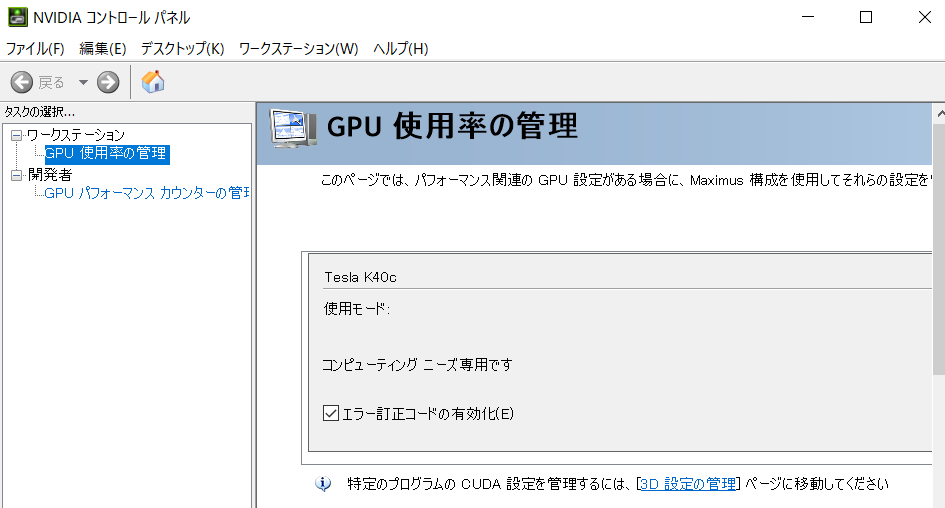
起動したら,こんな画面が表示されれば成功です.GPUを利用することが出来る状態になりました.
CuPyのインストール
次に,PythonでGPUを使うために必要になる,CuPyというライブラリをインストールします.これが色々とConflictを起こしがちなのですが,Anacondaベースの皆さんには怖くないはずです.蛇さんが勝手にやってくれます.

CuPyは,Pythonの数値計算時によく使うNumPyと呼ばれるライブラリの関数を基本的にトレースした互換性の高いライブラリで,NumPyで提供されている関数をNVIDIAのGPUで実行するようにしたものです.NVIDIAのGPUがないと無理といったのは,このCuPyが使えないことに起因します.
CuPy公式から,CuPyをインストールします.Anacondaがない場合,自身のCUDA等のバージョンに合わせて適切な方法を取らないと上手く動きませんが,Anacondaは簡単です.
Anaconda Navigatorを起動します.左のタブから,Environmentを選びます.
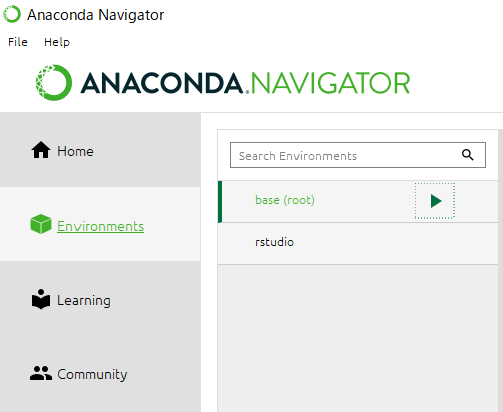
このような画面が出たら,base(root)の三角を押し,terminalを起動します.
conda install -c conda-forge cupy
を実行することで,Anacondaが環境にあったCuPyを自動でインストールしてくれるはずです.ただし,この場合は自分のドライバがサポートしているバージョンの中で最新のものがインストールされるので,何か特別の理由があってCUDAのバージョンを指定したい場合は
conda install -c conda-forge cupy cudatoolkit=xxx
などと指定することも可能です.xxxにバージョンを入れてください.
しばし待つと,問題なければインストールが完了します.
CuPyのテスト
インストールが終わったら,動作テストを行います.Notebookを開き,
import numpy as np
import cupy as cp
を実行してみてください.エラーを吐かなければインストールは無事成功しています.
では,CPUで計算するNumPyとGPUで計算するCuPyの性能比較をしてみましょう.基本的な使い方は一緒です.
import numpy as np
import cupy as cp
from skimage import data,transform,color,io
np_img = data.astronaut()#画像ロード
np_img = color.rgb2gray(np_img)#グレースケール化
np_img = np_img.astype('f')
io.imshow(np_img)#画像の表示
cp_img = cp.asarray(np_img)#numpy配列をcupy配列に変換
をセルにいれ,実行しましょう.すると

のように画像が表示できるはずです.skimageがない場合はインストールしてきてください.
これをNumPy, CuPyでそれぞれ無駄に疲れるフーリエ変換させてみます.
%%time
for i in range(500): # numpy 500セット(フーリエ変換⇒シフト⇒シフト⇒フーリエ逆変換->フーリエ逆変換->フーリエ変換)計算時間
np_img = np.fft.ifft(np.fft.fft(np_img))
np_fimg = np.fft.fft(np.fft.ifft(np.fft.fft(np_fimg)))
%%time
for i in range(500): # cupy 500セット(フーリエ変換->フーリエ逆変換->フーリエ変換->フーリエ逆変換->フーリエ変換)計算時間
cp_img = cp.fft.ifft(cp.fft.fft(cp_img))
cp_fimg = cp.fft.fft(cp.fft.ifft(cp.fft.fft(cp_fimg)))
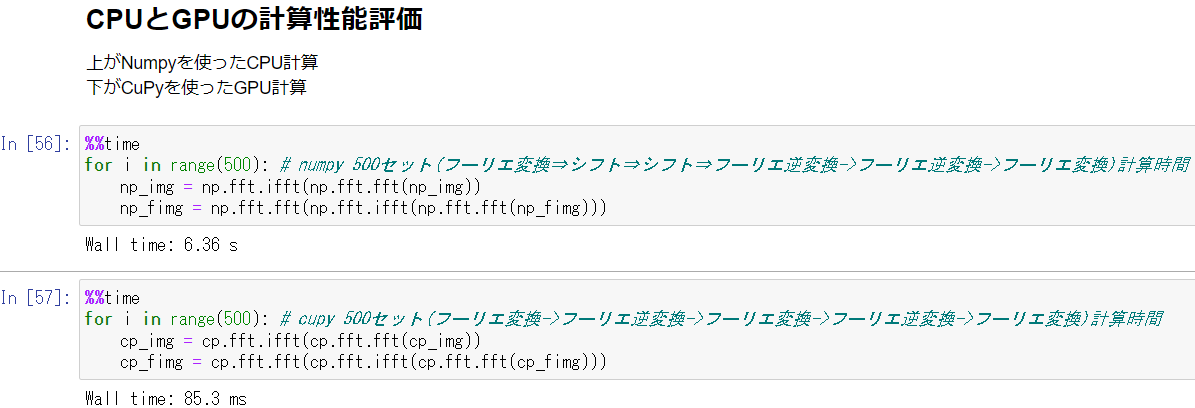
それぞれ実行してみると,CPUが6秒超えなのに対し,GPUは85msでした.かなり高速です.この差は実行する環境次第で変わりますが,問題によってはGPUの方が早いことが確認できました.